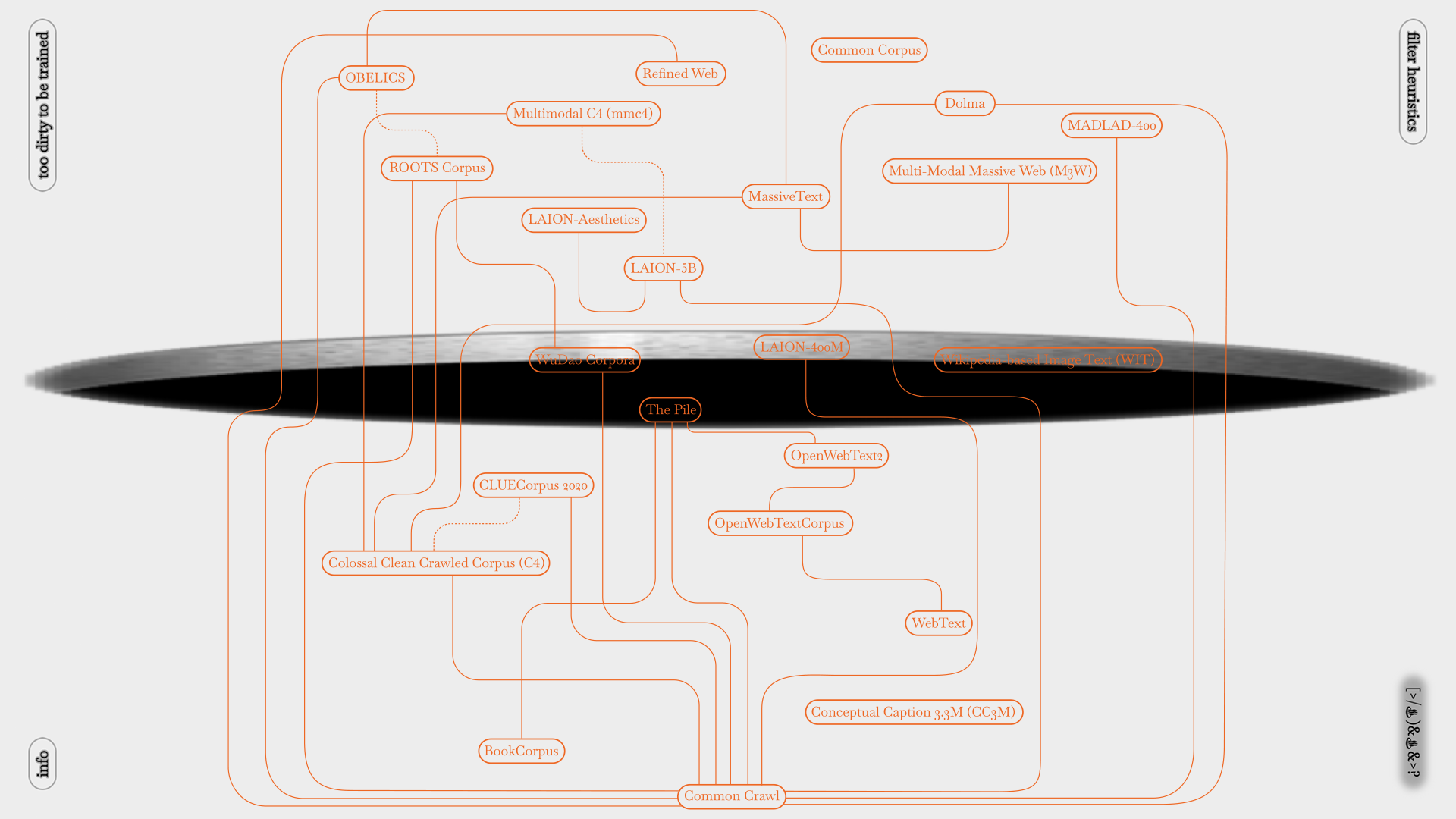
Datasets for pre-training large models have been expanded to the volume of (partial) internet, with the idea of “scale averages out noise”, these datasets scrape whatever is available on the internet, then “cleaned” with a human-not-in-the-loop, cheaper-than-cheap-labour method: heuristic filtering... Heuristics in this context are basically a set of rules created by some software engineers with their imagination and estimation that are “good enough” to remove “dirty data” from their perspective, not guaranteed to be optimal, perfect, or rational...
If we know, partially, what is considered as dirty, doesn’t it mean that we can make our data “dirty” and get it filtered out by following their rigid estimation� Can we opt out from being trained by becoming unqualified� sorri my data is too dirty for your model came up with a set of anti-heuristic heuristics based on 23 datasets to have our texts and images mingle and stay close to “dirty data”, purity is never an option 😈
On view in the exhibition "AMRO26: Becoming Unreadable" at SPLACE. Another jiawen uffline's artwork is on view in the exhibition Decay and Desire at bb15; also in conversation at AMRO Showcase night DH5.
Photo Credits: Jürgen Grünwald